Google Abandonó Gear por Html5
Google ha anunciado que no trabajara mas en Google Gears. Las razones son es que Google esta mudándose todas sus aplicaciones en la web a HTML5. Otra de las razones es que Google quiere crear una relación y sincronizar sus aplicaciones con la Web, llevar a la idea de la “Cloud Computing“
La adaptación de las funciones actuales de Google Gears hacia HTML5 aún no está completa, pero de acuerdo a las palabras oficiales, se encuentran muy cerca de alcanzar ese objetivo.
Aunque todavía se ve muy lejos en que se tome el HTML5 como algo universal y se cuestiona a Google está forzando de forma general la adopción de HTML5, pero en realidad es preferible que el traslado se realice hacia un estándar conocido y no se este recurriendo a extensiones y plugins.
Que es un Documento HTML ? Guía Rápida
Un documento en HTML («HyperText Markup Language») define la forma en que será desplegada información en un navegador («Netscape» o «Explorer»), este documento se compone de tags y contenido .
Un tag delimita el inicio y fin de cierto contenido, esto es, cada tag indica cuando se utilizarán letras negritas , cuando iniciarán letras rojas , la ubicación de gráficas y cualquier otra forma que influya en el despliegue de información.
Documento Básico
<html>
<head>
<title> Documento Básico en HTML </title>
</head>
<body>
<h2> Este es el Titulo </H2>
<!-- Este es un comentario de recordatorio
que no aparecerá en pantalla -->
<a href="mailto:webmaster@osmosislatina.com">
Envíame un Mail
</a>
</body>
</html>
|
Analizando el contenido del Documento básico se puede observar que los tags se encuentran definidos entre < y > ; el tag <title> indica que a partir del tag todo contenido será considerado información de Titulo, mientras el tag similar con / ( </title> ) indica que la información de Titulo ha terminado; el tag <!-- indica el inicio de un comentario y --> indica que el comentario termina.
Como generar el Documento
Para generar un documento en HTML es necesario utilizar un editor de textos si utiliza Windows este seria «Notepad» , no utilice «Word» , «Word» agrega un formato adicional al texto ( Editores WYSIWG ), para escribir un documento en HTML este debe ser solo texto , por lo tanto se debe utilizar un editor de textos para que no ocurra ningún tipo de formato adicional.
Una vez generado el documento, este debe de ser guardado con la extensión .html o .htm , esto garantiza que cada vez que sea abierto el documento vía un icono , este será desplegado por un Navegador («Netscape» o «Explorer»). También es posible desplegar (abrir) el documento mediante el menú : File | Open del Navegador.
Como opera el Navegador y consideraciones
Cuando un navegador («Netscape» o «Explorer») recibe cualquier documento y observa los tags , éste despliega el documento de acuerdo a los estándares establecidos por el Navegador (este proceso es conocido como rendering), a pesar de estos estándares en HTML ( Versión 4.01), existen varias discrepancias en su implementación, la gran mayoría de navegadores desde «Netscape»,»Explorer» y algunos otros utilizan tags que son implementados como propietarios, esto es, si se utiliza un tag para un color grisrojo desarrollado en el Navegador «Netscape» es muy probable que este tag no sea identificado por otros navegadores («Explorer») y por lo tanto no se obtenga el mismo resultado («visualización») en diferentes Navegadores.
Esta discrepancia en tags no solo se da en colores, sino en diversas áreas relacionadas con el navegador, el caso más delicado es cuando se desarrolla una aplicación de cliente que solo es capaz de ejecutarse en un tipo (marca) de Navegador.
Que es XHTML ?
XHTML («Extensible HyperText Markup Language») es la evolución de la ultima versión de HTML (4.01) hacia una nueva estructura y sintaxis de documentos distribuidos en ambientes Web basado en el estándar XML .
Entre las principales diferencias de HTML 4.01 a XHTML son :
- XHTML posee una sintaxis estrictamente apegada a XML a diferencia de HTML.
- La anulación («deprecation») de diversos tags HTML 4.01, no válidos en XHTML .
- Fuerte énfasis en el uso de CSS («Cascading Style Sheets») .
Creando Formularios en HTML
Formas y Aplicación de Servidor
La recabación de datos forma una parte muy importante para cualquier sitio de Internet y esta también se lleva acabo con elementos HTML denominados formas, los elementos principales de una forma son los tags <form> que indican como y a donde será enviada la información. Dentro de <form> se declaran dos atributos muy importantes, uno de ellos es method y el otro action .
<body> ...... ...... <form method="post" action="/cgi-bin/confirmar.pl"> ...... ...... </form> ..... </body> |
El atributo method le indica al navegador («Netscape» o «Explorer») como debe ser enviada la información al Servidor, este valor puede ser post o get , sin entrar en mucho detalle, si se utiliza get los elementos de la forma serán enviados al Servidor en el URL («Universal Resource Locator») de action, esto es, si dentro de la forma se solicitan los valores: nombre,edad y nacionalidad, la información sería enviada de la siguiente manera:
http://www.osmosislatina.com/cgi-bin/confirmar.pl? nombre=PedroMtz&edad=25&nacionalidad=americana |
Después del URL el navegador agrega ? para indicar que continúan variables solicitadas, a partir de ? continúan las variables definidas por medio de un = y separadas por un &, en cambio si se utiliza post las variables y sus valores se incluirán en el contenido de la requisición, por debajo del URL. Lo anterior garantiza que el usuario final no sea capaz de observar las variables en el URL, fuera de esto, la única implicación en utilizar post o get es que la aplicación de Servidor sea capaz de leer las variables y sus valores.
En el caso anterior la Aplicación de Servidor (Programa) que procesa esta información es aquella definida por el atributo action , la cual es un «script» en Perl llamado: confirmar.pl ; en otros casos esta Aplicación de Servidor pudo ser: Un JSP («Java Server Page») , ASP («Active Server Page»), PHP («Hypertext Preprocessor») u otra metodología de Servidor.
Tags input
El Tag input permite pasar un conjunto de variables con sus respectivos valores en una forma.
Tipo Text
Este tipo de variable permite al usuario final asignar un valor de texto a la variable en cuestión , se expresa de la siguiente manera:
País: <input type="text" name="pais" size="10" maxlength="20" value="mexico"> |
La declaración indica que será desplegado un recuadro de 10 espacios (size) donde la variable llevará por nombre pais, dicha variable puede tener un valor máximo de 20 letras (maxlength) y aparecerá un valor «default» mexico (este valor puede ser modificado por el usuario).
Tipo Password
También permite que el usuario especifique un valor de texto, pero a diferencia del tipo text el usuario observará asteriscos ( **** ) mas no el texto.
Contraseña: <input type="password" name="pass" size="15" maxlength="30"> |
NOTA: A pesar que el valor no aparece en pantalla, el valor no es protegido al momento de ser transferido al nivel de Red, para realizar esta protección se requiere utilizar encriptación en el Servidor de Paginas.
Tipo Radio
Este tipo de variable es utilizada para desplegar un menú con botones.
País:<input type="radio" name="pais" value="ar">Argentina
<input type="radio" name="pais" value="br">Brazil
<input type="radio" name="pais" value="co">Colombia
<input type="radio" name="pais" checked value="mx">México
<input type="radio" name="pais" value="ve">Venezuela
|
Lo anterior indica que el nombre de la variable pais será un menú de selección de botones, donde el valor «default» ( checked ) será México, los parámetros value indican el valor que tomará la variable en caso de ser seleccionada; value es de gran ayuda cuando la descripción de la variable es extensa y solo se desea enviar un vocablo o iniciales como valor al Servidor de Paginas, si se omite el valor value , el valor de la variable pasa a ser aquel que se encuentra del lado derecho del elemento.
Tipo Checkbox
Este tipo de variable es utilizada para desplegar un menú con cuadros de selección, a diferencia del tipo Radio , Checkbox permite la selección de múltiples valores :
Intereses:<input type="checkbox" name="intereses" value="p">Política
<input type="checkbox" name="intereses" checked value="d">Deportes
<input type="checkbox" name="intereses" value="c">Cine
<input type="checkbox" name="intereses" checked value="t">Tecnología
<input type="checkbox" name="intereses" value="a">Administración
|
Los parámetros que son utilizados para este tipo de variable tienen el mismo funcionamiento que el Tipo radio ( name, checked, value), la única diferencia es que si son seleccionados varios valores, la información es pasada al Servidor de Paginas como: intereses="d" intereses="t" , por lo tanto debe asegurarse que su Aplicación de Servidor sea capaz de procesar dos o más valores para la misma variable.
Tipo Hidden
Este tipo de elemento es utilizado para esconder el valor de cierta variable, se utiliza generalmente cuando es necesario procesar datos a lo largo de dos o tres paginas, de esta manera la variable sigue existiendo en la forma, pero no es desplegada en pantalla.
<input type="hidden" name="intereses">
<input type="hidden" name="pais" value="mexico">
|
Tag select
El Tag select permite generar menús de una manera similar a las mencionadas anteriormente.
<select size="3" name="intereses" multiple> <option value="p">Política <option value="t" selected>Tecnología <option value="d">Deportes <option value="c">Cine <option value="m">Música </select> |
Los parámetros del Tag select son:
name: Indica el nombre de la variable (como los Taginput).size: Especifica el número de opciones que serán desplegadas en pantalla ( las restantes serán incluidas en forma de menú).multiple(opcional): Permite al usuario final elegir varios valores (si se omitemultiplesolo se permite seleccionar un valor, como el comportamiento del input radio ); para seleccionar diversos elementos de manera aleatoria, se oprime del tecladoCtrl.<option>: Define los valores de la variable en cuestión, dentro de estos tags es posible indicar el parámetrovalueque tiene el mismo funcionamiento que los Tags input , yselectedque permite preseleccionar ciertos valores.
Tag textarea
Los Tags textarea son muy similares a input text , la diferencia estriba en que textarea permite definir el área por renglones y columnas.
El parámetro name indica el nombre de la variable que llevará el contenido, mientras cols y rows definen el espacio que es visible en pantalla, cualquier texto que aparezca entre los tags textarea será desplegado dentro del recuadro.
El primer documento HTML
Las páginas HTML se dividen en dos partes: la cabecera y el cuerpo. La cabecera incluye información sobre la propia página, como por ejemplo su título y su idioma. El cuerpo de la página incluye todos sus contenidos, como párrafos de texto e imágenes
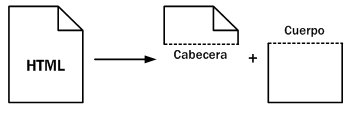
Esquema de las partes que forman un documento HTML
El cuerpo (llamado body en inglés) contiene todo lo que el usuario ve en su pantalla y la cabecera (llamada head en inglés) contiene todo lo que no se ve (con la única excepción del título de la página, que los navegadores muestran como título de sus ventanas).
A continuación se muestra el código HTML de una página web muy sencilla:
<html> <head> <title>El primer documento HTML</title> </head> <body> <p>El lenguaje HTML es <strong>tan sencillo</strong> que prácticamente se entiende sin estudiar el significado de sus etiquetas principales.</p> </body> </html>
Si quieres probar este primer ejemplo, debes hacer lo siguiente:
- Abre un editor de archivos de texto y crea un archivo nuevo
- Copia el código HTML mostrado anteriormente y pégalo tal cual en el archivo que has creado
- Guarda el archivo con el nombre que quieras, pero con la extensión
.html
Para que el ejemplo anterior funcione correctamente, es imprescindible que utilices un editor de texto sin formato. Si tu sistema operativo es Windows, puedes utilizar el Bloc de notas, Wordpad, EmEditor, UltraEdit, Notepad++, etc. pero no puedes utilizar un procesador de textos como Word o Open Office. Si utilizas sistemas operativos tipo Linux, puedes utilizar editores como Gedit, Kedit, Kate e incluso Vi, pero no utilices KOffice ni Open Office.
Características básicas de XHTML
Lenguajes de etiquetas
Uno de los retos iniciales a los que se tuvo que enfrentar la informática fue el de cómo almacenar la información en los archivos digitales. Como los primeros archivos sólo contenían texto sin formato, la solución utilizada era muy sencilla: se codificaban las letras del alfabeto y se transformaban en números.
De esta forma, para almacenar un contenido de texto en un archivo electrónico, se utiliza una tabla de conversión que transforma cada carácter en un número. Una vez almacenada la secuencia de números, el contenido del archivo se puede recuperar realizando el proceso inverso.

Ejemplo sencillo de codificación de caracteres
El proceso de transformación de caracteres en secuencias de números se denomina codificación de caracteres y cada una de las tablas que se han definido para realizar la transformación se conocen con el nombre de páginas de código. Una de las codificaciones más conocidas (y una de las primeras que se publicaron) es la codificación ASCII. La importancia de las codificaciones en HTML se verá más adelante.
Una vez resuelto el problema de almacenar el texto simple, se presenta el reto de almacenar los contenidos de texto con formato. En otras palabras, ¿cómo se almacena un texto en negrita? ¿y un texto de color rojo? ¿y otro texto azul, en negrita y subrayado?
Utilizar una tabla de conversión similar a las que se utilizan para textos sin formato no es posible, ya que existen infinitos posibles estilos para aplicar al texto. Una solución técnicamente viable consiste en almacenar la información sobre el formato del texto en una zona especial reservada dentro del propio archivo. En esta zona se podría indicar dónde comienza y dónde termina cada formato.
No obstante, la solución que realmente se emplea para guardar la información con formato es mucho más sencilla: el archivo electrónico almacena tanto los contenidos como la información sobre el formato de esos contenidos. Si por ejemplo se quiere dividir el texto en párrafos y se desea dar especial importancia a algunas palabras, se podría indicar de la siguiente manera:
<parrafo> Contenido de texto con <importante>algunas palabras</importante> resaltadas de forma especial. </parrafo>
El principio de un párrafo se indica mediante la palabra <parrafo> y el final de un párrafo se indica mediante la palabra </parrafo>. De la misma manera, para asignar más importancia a ciertas palabras del texto, se encierran entre <importante> y </importante>.
El proceso de indicar las diferentes partes que componen la información se denomina marcar (markup en inglés). Cada una de las palabras que se emplean para marcar el inicio y el final de una sección se denominan etiquetas.
Aunque existen algunas excepciones, en general las etiquetas se indican por pares y se forman de la siguiente manera:
- Etiqueta de apertura: carácter
<, seguido del nombre de la etiqueta (sin espacios en blanco) y terminado con el carácter> - Etiqueta de cierre: carácter
<, seguido del carácter/, seguido del nombre de la etiqueta (sin espacios en blanco) y terminado con el carácter>
Así, la estructura típica de las etiquetas HTML es:
<nombre_etiqueta> ... </nombre_etiqueta>
HTML es un lenguaje de etiquetas (también llamado lenguaje de marcado) y las páginas web habituales están formadas por cientos o miles de pares de etiquetas. De hecho, las letras «ML» de la sigla HTML significan «markup language», que es como se denominan en inglés a los lenguajes de marcado. Además de HTML, existen muchos otros lenguajes de etiquetas como XML, SGML, DocBook y MathML.
La principal ventaja de los lenguajes de etiquetas es que son muy sencillos de leer y escribir por parte de las personas y de los sistemas electrónicos. La principal desventaja es que pueden aumentar mucho el tamaño del documento, por lo que en general se utilizan etiquetas con nombres muy cortos.
HTML y CSS
Originalmente, las páginas HTML sólo incluían información sobre sus contenidos de texto e imagenes. Con el desarrollo del estándar HTML, las páginas empezaron a incluir también información sobre el aspecto de sus contenidos: tipos de letra, colores y márgenes.
La posterior aparición de tecnologías como JavaScript, provocaron que las páginas HTML también incluyeran el código de las aplicaciones (llamadas scripts) que se utilizan para crear páginas web dinámicas.
Incluir en una misma página HTML los contenidos, el diseño y la programación complica en exceso su mantenimiento. Normalmente, los contenidos y el diseño de la página web son responsabilidad de diferentes personas, por lo que es conveniente separarlos.
CSS es el mecanismo que permite separar los contenidos definidos mediante XHTML y el aspecto que deben presentar esos contenidos:

Esquema de la separación de los contenidos y su presentación
Una ventaja añadida de la separación de los contenidos y su presentación es que los documentos XHTML creados son más flexibles, ya que se adaptan mejor a las diferentes plataformas: pantallas de ordenador, pantallas de dispositivos móviles, impresoras y dispositivos utilizados por personas discapacitadas.
De esta forma, utilizando exclusivamente XHTML se crean páginas web «feas» pero correctas. Aplicando CSS, se pueden crear páginas «bonitas» a partir de las páginas XHTML correctas.
HTML y XHTML
El lenguaje XHTML es muy similar al lenguaje HTML. De hecho, XHTML no es más que una adaptación de HTML al lenguaje XML. Técnicamente, HTML es descendiente directo del lenguaje SGML, mientras que XHTML lo es del XML (que a su vez, también es descendiente de SGML).

Esquema de la evolución de HTML y XHTML
Las páginas y documentos creados con XHTML son muy similares a las páginas y documentos HTML. Las discusiones sobre si HTML es mejor que XHTML o viceversa son recurrentes en el ámbito de la creación de contenidos web, aunque no existe una conclusión ampliamente aceptada.
Actualmente, entre HTML 4.01 y XHTML 1.0, la mayoría de diseñadores escogen XHTML. En un futuro cercano, si los diseñadores deben elegir entre HTML 5 y XHTML 1.1 o XHTML 2.0, quizás la elección sea diferente.
Especificación oficial de HTML
El organismo W3C (World Wide Web Consortium) elabora las normas que deben seguir los diseñadores de páginas web para crear las páginas HTML. Las normas oficiales están escritas en inglés y se pueden consultar de forma gratuita en las siguientes direcciones:
El estándar XHTML 1.0 incluye el 95% del estándar HTML 4.01, ya que sólo añade pequeñas mejoras y modificaciones menores. Afortunadamente, no es necesario leer las especificaciones y recomendaciones oficiales de HTML para aprender a diseñar páginas con HTML o XHTML. Las normas oficiales están escritas con un lenguaje bastante formal y algunas secciones son difíciles de comprender. Por ello, en los próximos capítulos se explica de forma sencilla y con decenas de ejemplos la especificación oficial de XHTML.
Breve historia de HTML
La historia completa de HTML es tan interesante como larga, por lo que a continuación se muestra su historia resumida a partir de la información que se puede encontrar en la Wikipedia.
El origen de HTML se remonta a 1980, cuando el físico Tim Berners-Lee, trabajador del CERN (Organización Europea para la Investigación Nuclear) propuso un nuevo sistema de «hipertexto» para compartir documentos.
Los sistemas de «hipertexto» habían sido desarrollados años antes. En el ámbito de la informática, el «hipertexto» permitía que los usuarios accedieran a la información relacionada con los documentos electrónicos que estaban visualizando. De cierta manera, los primitivos sistemas de «hipertexto» podrían asimilarse a los enlaces de las páginas web actuales.
Tras finalizar el desarrollo de su sistema de «hipertexto», Tim Berners-Lee lo presentó a una convocatoria organizada para desarrollar un sistema de «hipertexto» para Internet. Después de unir sus fuerzas con el ingeniero de sistemas Robert Cailliau, presentaron la propuesta ganadora llamada WorldWideWeb (W3).
El primer documento formal con la descripción de HTML se publicó en 1991 bajo el nombre «HTML Tags» (Etiquetas HTML) y todavía hoy puede ser consultado online a modo de reliquia informática.
La primera propuesta oficial para convertir HTML en un estándar se realizó en 1993 por parte del organismo IETF (Internet Engineering Task Force). Aunque se consiguieron avances significativos (en esta época se definieron las etiquetas para imágenes, tablas y formularios) ninguna de las dos propuestas de estándar, llamadas HTML y HTML+ consiguieron convertirse en estándar oficial.
En 1995, el organismo IETF organiza un grupo de trabajo de HTML y consigue publicar, el 22 de septiembre de ese mismo año, el estándar HTML 2.0. A pesar de su nombre, HTML 2.0 es el primer estándar oficial de HTML.
A partir de 1996, los estándares de HTML los publica otro organismo de estandarización llamado W3C (World Wide Web Consortium). La versión HTML 3.2 se publicó el 14 de Enero de 1997 y es la primera recomendación de HTML publicada por el W3C. Esta revisión incorpora los últimos avances de las páginas web desarrolladas hasta 1996, como applets de Java y texto que fluye alrededor de las imágenes.
HTML 4.0 se publicó el 24 de Abril de 1998 (siendo una versión corregida de la publicación original del 18 de Diciembre de 1997) y supone un gran salto desde las versiones anteriores. Entre sus novedades más destacadas se encuentran las hojas de estilos CSS, la posibilidad de incluir pequeños programas o scripts en las páginas web, mejora de la accesibilidad de las páginas diseñadas, tablas complejas y mejoras en los formularios.
La última especificación oficial de HTML se publicó el 24 de diciembre de 1999 y se denomina HTML 4.01. Se trata de una revisión y actualización de la versión HTML 4.0, por lo que no incluye novedades significativas.
Desde la publicación de HTML 4.01, la actividad de estandarización de HTML se detuvo y el W3C se centró en el desarrollo del estándar XHTML. Por este motivo, en el año 2004, las empresas Apple, Mozilla y Opera mostraron su preocupación por la falta de interés del W3C en HTML y decidieron organizarse en una nueva asociación llamada WHATWG (Web Hypertext Application Technology Working Group).
La actividad actual del WHATWG se centra en el futuro estándar HTML 5, cuyo primer borrador oficial se publicó el 22 de enero de 2008. Debido a la fuerza de las empresas que forman el grupo WHATWG y a la publicación de los borradores de HTML 5.0, en marzo de 2007 el W3C decidió retomar la actividad estandarizadora de HTML.
De forma paralela a su actividad con HTML, W3C ha continuado con la estandarización de XHTML, una versión avanzada de HTML y basada en XML. La primera versión de XHTML se denomina XHTML 1.0 y se publicó el 26 de Enero de 2000 (y posteriormente se revisó el 1 de Agosto de 2002).
XHTML 1.0 es una adaptación de HTML 4.01 al lenguaje XML, por lo que mantiene casi todas sus etiquetas y características, pero añade algunas restricciones y elementos propios de XML. La versión XHTML 1.1 ya ha sido publicada en forma de borrador y pretende modularizar XHTML. También ha sido publicado el borrador de XHTML 2.0, que supondrá un cambio muy importante respecto de las anteriores versiones de XHTML.
Qué es HTML
Definiéndolo de forma sencilla, «HTML es lo que se utiliza para crear todas las páginas web de Internet». Más concretamente, HTML es el lenguaje con el que se «escriben» la mayoría de páginas web.
Los diseñadores utilizan el lenguaje HTML para crear sus páginas web, los programas que utilizan los diseñadores generan páginas escritas en HTML y los navegadores que utilizamos los usuarios muestran las páginas web después de leer su contenido HTML.
Aunque HTML es un lenguaje que utilizan los ordenadores y los programas de diseño, es muy fácil de aprender y escribir por parte de las personas. En realidad, HTML son las siglas de HyperText Markup Language y más adelante se verá el significado de cada una de estas palabras.
El lenguaje HTML es un estándar reconocido en todo el mundo y cuyas normas define un organismo sin ánimo de lucro llamado World Wide Web Consortium, más conocido como W3C. Como se trata de un estándar reconocido por todas las empresas relacionadas con el mundo de Internet, una misma página HTML se visualiza de forma muy similar en cualquier navegador de cualquier sistema operativo.
El propio W3C define el lenguaje HTML como «un lenguaje reconocido universalmente y que permite publicar información de forma global». Desde su creación, el lenguaje HTML ha pasado de ser un lenguaje utilizado exclusivamente para crear documentos electrónicos a ser un lenguaje que se utiliza en muchas aplicaciones electrónicas como buscadores, tiendas online y banca electrónica.